
A basic syntax guide for T-SQL, used by SQL Server and Azure SQL Database, Azure Synapse Analytics and Parallel Data Warehouse
Source - Microsoft T-SQL Reference
Table of Contents
- Types of SQL Commands
Types of SQL Commands
- DDL Data Definition Language
- CREATE, ALTER, DROP, RENAME, TRUNCATE, COMMENT
- DQL Data Query Language
- SELECT
- DML Data Manipulation Language
- INSERT, UPDATE, DELETE, MERGE, CALL, EXPLAIN PLAN, LOCK TABLE
- DCL Data Control Language
- GRANT, REVOKE
SELECT
Reading objects from the database
Syntax
<SELECT statement> ::=
[ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ]
<query_expression>
[ ORDER BY { order_by_expression | column_position [ ASC | DESC ] }
[ ,...n ] ]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
Example
SELECT *
FROM DimEmployee
ORDER BY LastName;
SELECT INTO
Inserting records into the database which are derived from other data
Syntax
[ INTO new_table ]
[ ON filegroup ]
Example
SELECT c.FirstName, c.LastName, e.JobTitle, a.AddressLine1, a.City,
sp.Name AS [State/Province], a.PostalCode
INTO dbo.EmployeeAddresses
FROM Person.Person AS c
JOIN HumanResources.Employee AS e
ON e.BusinessEntityID = c.BusinessEntityID
JOIN Person.BusinessEntityAddress AS bea
ON e.BusinessEntityID = bea.BusinessEntityID
JOIN Person.Address AS a
ON bea.AddressID = a.AddressID
JOIN Person.StateProvince as sp
ON sp.StateProvinceID = a.StateProvinceID;
GO
SELECT OVER
Reads objects from the database, after defining a window or subset of record to query
Syntax
-- Syntax for SQL Server, Azure SQL Database, and Azure SQL Data Warehouse
OVER (
[ <PARTITION BY clause> ]
[ <ORDER BY clause> ]
[ <ROW or RANGE clause> ]
)
<PARTITION BY clause> ::=
PARTITION BY value_expression , ... [ n ]
<ORDER BY clause> ::=
ORDER BY order_by_expression
[ COLLATE collation_name ]
[ ASC | DESC ]
[ ,...n ]
<ROW or RANGE clause> ::=
{ ROWS | RANGE } <window frame extent>
<window frame extent> ::=
{ <window frame preceding>
| <window frame between>
}
<window frame between> ::=
BETWEEN <window frame bound> AND <window frame bound>
<window frame bound> ::=
{ <window frame preceding>
| <window frame following>
}
<window frame preceding> ::=
{
UNBOUNDED PRECEDING
| <unsigned_value_specification> PRECEDING
| CURRENT ROW
}
<window frame following> ::=
{
UNBOUNDED FOLLOWING
| <unsigned_value_specification> FOLLOWING
| CURRENT ROW
}
<unsigned value specification> ::=
{ <unsigned integer literal> }
Example
USE AdventureWorks2012;
GO
SELECT ROW_NUMBER() OVER(PARTITION BY PostalCode ORDER BY SalesYTD DESC) AS "Row Number",
p.LastName, s.SalesYTD, a.PostalCode
FROM Sales.SalesPerson AS s
INNER JOIN Person.Person AS p
ON s.BusinessEntityID = p.BusinessEntityID
INNER JOIN Person.Address AS a
ON a.AddressID = p.BusinessEntityID
WHERE TerritoryID IS NOT NULL
AND SalesYTD <> 0
ORDER BY PostalCode;
GO
INSERT
Adding records into the database
Syntax
-- Syntax for SQL Server and Azure SQL Database
[ WITH <common_table_expression> [ ,...n ] ]
INSERT
{
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ]
{ <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
{
[ ( column_list ) ]
[ <OUTPUT Clause> ]
{ VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) [ ,...n ]
| derived_table
| execute_statement
| <dml_table_source>
| DEFAULT VALUES
}
}
}
[;]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name
}
<dml_table_source> ::=
SELECT <select_list>
FROM ( <dml_statement_with_output_clause> )
[AS] table_alias [ ( column_alias [ ,...n ] ) ]
[ WHERE <search_condition> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
Example
INSERT INTO Cities (Location)
VALUES ( CONVERT(Point, '12.3:46.2') );
UPDATE
Modifying a set of records in the database
Syntax
-- Syntax for SQL Server and Azure SQL Database
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
Example
USE AdventureWorks2012;
GO
UPDATE Sales.SalesPerson
SET Bonus = 6000, CommissionPct = .10, SalesQuota = NULL;
GO
DELETE
Removing records from the database
Syntax
-- Syntax for SQL Server and Azure SQL Database
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}
Example
DELETE FROM Production.ProductCostHistory
WHERE StandardCost > 1000.00;
GO
ALTER
ALTER TABLE ADD COLUMN
Syntax
ALTER TABLE table_name
ADD (Columnname_1 datatype,
Columnname_2 datatype,
…
Columnname_n datatype);
Example
ALTER TABLE Student ADD (AGE number(3),COURSE varchar(40));
ALTER TABLE DROP COLUMN
Syntax
ALTER TABLE table_name
DROP COLUMN column_name;
Example
ALTER TABLE Student DROP COLUMN COURSE;
ALTER TABLE ALTER COLUMN
Syntax
ALTER TABLE table_name
ALTER COLUMN column_name column_type;
Example
ALTER TABLE Student ALTER COLUMN COURSE varchar(50)
CREATE
CREATE DATABASE
Syntax
CREATE DATABASE database_name;
Example
CREATE DATABASE Retail;
Syntax (COMPLETE)
CREATE DATABASE database_name
[ CONTAINMENT = { NONE | PARTIAL } ]
[ ON
[ PRIMARY ] <filespec> [ ,...n ]
[ , <filegroup> [ ,...n ] ]
[ LOG ON <filespec> [ ,...n ] ]
]
[ COLLATE collation_name ]
[ WITH <option> [,...n ] ]
[;]
<option> ::=
{
FILESTREAM ( <filestream_option> [,...n ] )
| DEFAULT_FULLTEXT_LANGUAGE = { lcid | language_name | language_alias }
| DEFAULT_LANGUAGE = { lcid | language_name | language_alias }
| NESTED_TRIGGERS = { OFF | ON }
| TRANSFORM_NOISE_WORDS = { OFF | ON}
| TWO_DIGIT_YEAR_CUTOFF = <two_digit_year_cutoff>
| DB_CHAINING { OFF | ON }
| TRUSTWORTHY { OFF | ON }
| PERSISTENT_LOG_BUFFER=ON ( DIRECTORY_NAME='<Filepath to folder on DAX formatted volume>' )
}
<filestream_option> ::=
{
NON_TRANSACTED_ACCESS = { OFF | READ_ONLY | FULL }
| DIRECTORY_NAME = 'directory_name'
}
<filespec> ::=
{
(
NAME = logical_file_name ,
FILENAME = { 'os_file_name' | 'filestream_path' }
[ , SIZE = size [ KB | MB | GB | TB ] ]
[ , MAXSIZE = { max_size [ KB | MB | GB | TB ] | UNLIMITED } ]
[ , FILEGROWTH = growth_increment [ KB | MB | GB | TB | % ] ]
)
}
<filegroup> ::=
{
FILEGROUP filegroup name [ [ CONTAINS FILESTREAM ] [ DEFAULT ] | CONTAINS MEMORY_OPTIMIZED_DATA ]
<filespec> [ ,...n ]
}
<service_broker_option> ::=
{
ENABLE_BROKER
| NEW_BROKER
| ERROR_BROKER_CONVERSATIONS
}
Example
USE master;
GO
IF DB_ID (N'mytest') IS NOT NULL
DROP DATABASE mytest;
GO
CREATE DATABASE mytest;
GO
-- Verify the database files and sizes
SELECT name, size, size*1.0/128 AS [Size in MBs]
FROM sys.master_files
WHERE name = N'mytest';
GO
CREATE TABLE
Syntax
-- Simple CREATE TABLE Syntax (common if not using options)
CREATE TABLE
{ database_name.schema_name.table_name. | schema_name.table_name | table_name }
( { <column_definition> } [ ,...n ] )
[ ; ]
Example
CREATE TABLE dbo.Employee (
EmployeeID INT PRIMARY KEY CLUSTERED
);
CREATE PROCEDURE
Syntax
-- Transact-SQL Syntax for Stored Procedures in SQL Server and Azure SQL Database
CREATE [ OR ALTER ] { PROC | PROCEDURE }
[schema_name.] procedure_name [ ; number ]
[ { @parameter [ type_schema_name. ] data_type }
[ VARYING ] [ = default ] [ OUT | OUTPUT | [READONLY]
] [ ,...n ]
[ WITH <procedure_option> [ ,...n ] ]
[ FOR REPLICATION ]
AS { [ BEGIN ] sql_statement [;] [ ...n ] [ END ] }
[;]
<procedure_option> ::=
[ ENCRYPTION ]
[ RECOMPILE ]
[ EXECUTE AS Clause ]
Examples
-
Simple Transact-SQL Procedure
CREATE PROCEDURE HumanResources.uspGetAllEmployees AS SET NOCOUNT ON; SELECT LastName, FirstName, JobTitle, Department FROM HumanResources.vEmployeeDepartment; GO SELECT * FROM HumanResources.vEmployeeDepartment; -
Returning multiple sets
CREATE PROCEDURE dbo.uspMultipleResults AS SELECT TOP(10) BusinessEntityID, Lastname, FirstName FROM Person.Person; SELECT TOP(10) CustomerID, AccountNumber FROM Sales.Customer; GO -
Procedures with input parameters
IF OBJECT_ID ( 'HumanResources.uspGetEmployees', 'P' ) IS NOT NULL DROP PROCEDURE HumanResources.uspGetEmployees; GO CREATE PROCEDURE HumanResources.uspGetEmployees @LastName nvarchar(50), @FirstName nvarchar(50) AS SET NOCOUNT ON; SELECT FirstName, LastName, JobTitle, Department FROM HumanResources.vEmployeeDepartment WHERE FirstName = @FirstName AND LastName = @LastName; GO -
Output Parameters
IF OBJECT_ID ( 'Production.uspGetList', 'P' ) IS NOT NULL DROP PROCEDURE Production.uspGetList; GO CREATE PROCEDURE Production.uspGetList @Product varchar(40) , @MaxPrice money , @ComparePrice money OUTPUT , @ListPrice money OUT AS SET NOCOUNT ON; SELECT p.[Name] AS Product, p.ListPrice AS 'List Price' FROM Production.Product AS p JOIN Production.ProductSubcategory AS s ON p.ProductSubcategoryID = s.ProductSubcategoryID WHERE s.[Name] LIKE @Product AND p.ListPrice < @MaxPrice; -- Populate the output variable @ListPprice. SET @ListPrice = (SELECT MAX(p.ListPrice) FROM Production.Product AS p JOIN Production.ProductSubcategory AS s ON p.ProductSubcategoryID = s.ProductSubcategoryID WHERE s.[Name] LIKE @Product AND p.ListPrice < @MaxPrice); -- Populate the output variable @compareprice. SET @ComparePrice = @MaxPrice; GO
CREATE FUNCTION
Syntax
-- Transact-SQL Scalar Function Syntax
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type
[ = default ] [ READONLY ] }
[ ,...n ]
]
)
RETURNS return_data_type
[ WITH <function_option> [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN scalar_expression
END
[ ; ]
Examples
-
Scalar function
CREATE FUNCTION dbo.ISOweek (@DATE datetime) RETURNS int WITH EXECUTE AS CALLER AS BEGIN DECLARE @ISOweek int; SET @ISOweek= DATEPART(wk,@DATE)+1 -DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104'); --Special cases: Jan 1-3 may belong to the previous year IF (@ISOweek=0) SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1 AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1; --Special case: Dec 29-31 may belong to the next year IF ((DATEPART(mm,@DATE)=12) AND ((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28)) SET @ISOweek=1; RETURN(@ISOweek); END; GO SET DATEFIRST 1; SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week'; -
Inline table function
CREATE FUNCTION Sales.ufn_SalesByStore (@storeid int) RETURNS TABLE AS RETURN ( SELECT P.ProductID, P.Name, SUM(SD.LineTotal) AS 'Total' FROM Production.Product AS P JOIN Sales.SalesOrderDetail AS SD ON SD.ProductID = P.ProductID JOIN Sales.SalesOrderHeader AS SH ON SH.SalesOrderID = SD.SalesOrderID JOIN Sales.Customer AS C ON SH.CustomerID = C.CustomerID WHERE C.StoreID = @storeid GROUP BY P.ProductID, P.Name ); GO -
Table value function
CREATE FUNCTION dbo.ufn_FindReports (@InEmpID INTEGER) RETURNS @retFindReports TABLE ( EmployeeID int primary key NOT NULL, FirstName nvarchar(255) NOT NULL, LastName nvarchar(255) NOT NULL, JobTitle nvarchar(50) NOT NULL, RecursionLevel int NOT NULL ) --Returns a result set that lists all the employees who report to the --specific employee directly or indirectly.*/ AS BEGIN WITH EMP_cte(EmployeeID, OrganizationNode, FirstName, LastName, JobTitle, RecursionLevel) -- CTE name and columns AS ( -- Get the initial list of Employees for Manager n SELECT e.BusinessEntityID, e.OrganizationNode, p.FirstName, p.LastName, e.JobTitle, 0 FROM HumanResources.Employee e INNER JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID WHERE e.BusinessEntityID = @InEmpID UNION ALL -- Join recursive member to anchor SELECT e.BusinessEntityID, e.OrganizationNode, p.FirstName, p.LastName, e.JobTitle, RecursionLevel + 1 FROM HumanResources.Employee e INNER JOIN EMP_cte ON e.OrganizationNode.GetAncestor(1) = EMP_cte.OrganizationNode INNER JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID ) -- copy the required columns to the result of the function INSERT @retFindReports SELECT EmployeeID, FirstName, LastName, JobTitle, RecursionLevel FROM EMP_cte RETURN END; GO -- Example invocation SELECT EmployeeID, FirstName, LastName, JobTitle, RecursionLevel FROM dbo.ufn_FindReports(1); GO
CREATE TRIGGER
Syntax
-- SQL Server Syntax
-- Trigger on an INSERT, UPDATE, or DELETE statement to a table or view (DML Trigger)
CREATE [ OR ALTER ] TRIGGER [ schema_name . ]trigger_name
ON { table | view }
[ WITH <dml_trigger_option> [ ,...n ] ]
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ] }
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
AS { sql_statement [ ; ] [ ,...n ] | EXTERNAL NAME <method specifier [ ; ] > }
<dml_trigger_option> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
<method_specifier> ::=
assembly_name.class_name.method_name
Example
CREATE TRIGGER reminder2
ON Sales.Customer
AFTER INSERT, UPDATE, DELETE
AS
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'AdventureWorks2012 Administrator',
@recipients = 'danw@Adventure-Works.com',
@body = 'Don`t forget to print a report for the sales force.',
@subject = 'Reminder';
GO
CREATE VIEW
Syntax
-- Syntax for SQL Server and Azure SQL Database
CREATE [ OR ALTER ] VIEW [ schema_name . ] view_name [ (column [ ,...n ] ) ]
[ WITH <view_attribute> [ ,...n ] ]
AS select_statement
[ WITH CHECK OPTION ]
[ ; ]
<view_attribute> ::=
{
[ ENCRYPTION ]
[ SCHEMABINDING ]
[ VIEW_METADATA ]
}
Example
-
Simple View
CREATE VIEW hiredate_view AS SELECT p.FirstName, p.LastName, e.BusinessEntityID, e.HireDate FROM HumanResources.Employee e JOIN Person.Person AS p ON e.BusinessEntityID = p.BusinessEntityID ; GO -
Partitioned View (Union all)
--Partitioned view as defined on Server1 CREATE VIEW Customers AS --Select from local member table. SELECT * FROM CompanyData.dbo.Customers_33 UNION ALL --Select from member table on Server2. SELECT * FROM Server2.CompanyData.dbo.Customers_66 UNION ALL --Select from member table on Server3. SELECT * FROM Server3.CompanyData.dbo.Customers_99; -
Encryption
CREATE VIEW Purchasing.PurchaseOrderReject WITH ENCRYPTION AS SELECT PurchaseOrderID, ReceivedQty, RejectedQty, RejectedQty / ReceivedQty AS RejectRatio, DueDate FROM Purchasing.PurchaseOrderDetail WHERE RejectedQty / ReceivedQty > 0 AND DueDate > CONVERT(DATETIME,'20010630',101) ; GO
Database Elements
Scripts
A script is a list of instructions which instruct an interpreter what operations to perform. The T-SQL (Transact-SQL) script notation describes how to interact with a database.
These scripts, which are called queries support the basic fundamental operations required in a typical data persistence scenario.
- Store Data
- Retrieve Data
- Modify Data
- Remove Data
- Protect Data
- Compress Data
- Convert Data
- Filter Data
Databases
A Database is a collection of entities and behaviors which can be used to represent information.
SQL Server is a Relational Database, meaning that the information stored in it, is comprised of records which are related to one another.
There are also Non-Relational database concepts which recently are becoming popular, which store records as documents. Non-relational database concepts can be used within SQL Server, but there are dedicated Non-Relational databases such as MongoDB, which typically require document related syntax which is not covered in this article.
Table
Data is stored in tables. In fact the system tables are used to store the definitions of entities, such as databases, tables, stored procedures, functions and view as well as other database entities within a database server.
Tables have data pages, which each have a specific type and contain parts of the table.
| Page type | Contents |
|---|---|
| Data | Data rows with all data, except text, ntext, image, nvarchar(max), varchar(max), varbinary(max), and xml data, when text in row is set to ON. |
| Index | Index entries. |
| Text/Image | Large object data types: (text, ntext, image, nvarchar(max), varchar(max), varbinary(max), and xml data) Variable length columns when the data row exceeds 8 KB: (varchar, nvarchar, varbinary, and sql_variant) |
| Global Allocation Map, Shared Global Allocation Map | Information about whether extents are allocated. |
| Page Free Space (PFS) | Information about page allocation and free space available on pages. |
| Index Allocation Map | Information about extents used by a table or index per allocation unit. |
| Bulk Changed Map | Information about extents modified by bulk operations since the last BACKUP LOG statement per allocation unit. |
| Differential Changed Map | Information about extents that have changed since the last BACKUP DATABASE statement per allocation unit. |
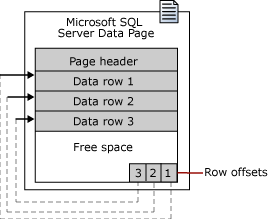
Column
Tables have Table Columns, or just Columns, as they are typically called. A Column definition must have at least a name and a data type. Columns may also contain other information including metadata, statistics, security, compression and hints.
In addition Tables will normally have a Primary Key defined, which is made up of one or more Table Columns, and helps access records by a chosen identifier.
Index
Indexes are defined on Tables and are used to accelerate the database query performance by assisting operations which read and join data.
There are two types of Indexes
- Clustered Indexes
- A clustered index enforces a sequence which the records are physically stored on the disk
- Data is therefore sorted by default
- Non-Clustered Indexes
- A non-clustered index records the order of specified columns within the collection of data pages which make up a table
- A record order is not enforced by a non-clustered index, so data is not sorted by default
Clustered Indexes are faster to read but slower to modify
Non-Clustered Indexes are faster to update but slower to read
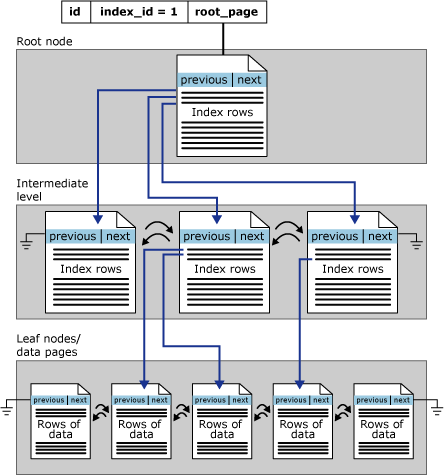
Indexes may have additional constraints
- Unique Indexes
- All record keys must be unique, per permutation
- Unique index constraints are typically used to ensure data integrity
- Filtered Indexes
- Return a well define subset of records from a large table
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate ON Production.BillOfMaterials (ComponentID, StartDate) WHERE EndDate IS NOT NULL ; GO - Columnstore Indexes
- A columnstore index is a technology for storing, retrieving and managing data by using a columnar data format, called a columnstore
- Typically SQL Server table indexes are Row Store, or records which are stored row by row. Conversely, a Columnstore index physically stores records column by column
- By storing records in a column store, compression is improved
- Hash Indexes
- Support memory optimized tables
- A hash index consists of an array of pointers, and each element of the array is called a hash bucket.
- Buckets contain entries which store a list of key entries
- Entries are a value of an index key
- A Hash function is used to determine which bucket a record belongs in
- Memory-Optimized Non-Clustered Indexes
View
Views are a projection of the data in tables, and as such do not themselves contain data. Views are used to perform create, read, update and delete operations on some combination of tables which together project the data types from one or more tables. They are therefore a powerful way of inspecting and manipulating data in context specific ways.
Cursors
Cursors are an extension of the original T-SQL script concepts to permit the record by record processing of a data set. Cursors are typically slow, and therefore set operations are generally preferred over Cursor updates.
Joins
There are several different types of joins which are supported via T-SQL
In the following join scenarios, these example tables will be included
Pet table
| PetId | OwnerId | PetName |
|---|---|---|
| 1 | A | Mr Tinkles |
| 2 | A | Spot |
| 3 | B | Rover |
| 4 | C | Rover |
Owner table
| OwnerId | OwnerName |
|---|---|
| A | Bill |
| B | Jane |
| C | Fred |
| D | Sam |
INNER JOIN
An INNER JOIN type ensures that only records which meet the join condition will be returned.
Inner Joining Pet table with Owner table on OwnerId
| Pet.PetId | Pet.OwnerId | Pet.PetName | Owner.OwnerID | Owner.OwnerName |
|---|---|---|---|---|
| 1 | A | Mr Tinkles | A | Bill |
| 2 | A | Spot | A | Bill |
| 3 | B | Rover | B | Jane |
| 4 | C | Rover | C | Fred |

Notes:
- Owner Sam (D) is not included in the results
OUTER JOIN or FULL OUTER JOIN or FULL JOIN
Outer Joining Pet table with Owner table on OwnerId
| Pet.PetId | Pet.OwnerId | Pet.PetName | Owner.OwnerID | Owner.OwnerName |
|---|---|---|---|---|
| 1 | A | Mr Tinkles | A | Bill |
| 2 | A | Spot | A | Bill |
| 3 | B | Rover | B | Jane |
| 4 | C | Rover | C | Fred |
| - | - | - | D | Sam |

LEFT OUTER JOIN or LEFT JOIN
Left Outer Joining Pet table with Owner table on OwnerId
| Pet.PetId | Pet.OwnerId | Pet.PetName | Owner.OwnerID | Owner.OwnerName |
|---|---|---|---|---|
| 1 | A | Mr Tinkles | A | Bill |
| 2 | A | Spot | A | Bill |
| 3 | B | Rover | B | Jane |
| 4 | C | Rover | C | Fred |
Notes:
- Pets is the left table
- Owners is the right table
- Owner Sam (D) is not found in the result set, because there are no Pets owned by Sam.

RIGHT OUTER JOIN or RIGHT JOIN
Right Outer Joining Pet table with Owner table on OwnerId
| Pet.PetId | Pet.OwnerId | Pet.PetName | Owner.OwnerID | Owner.OwnerName |
|---|---|---|---|---|
| 1 | A | Mr Tinkles | A | Bill |
| 2 | A | Spot | A | Bill |
| 3 | B | Rover | B | Jane |
| 4 | C | Rover | C | Fred |
| - | - | - | D | Sam |
Notes:
- Pets is the left table.
- Owners is the right table
- Owner Sam (D) is found in the result set, because Sam is on the table on the right.

Nested Loop Joins
If one join input is small (fewer than 10 rows) and the other join input is fairly large and indexed on its join columns, an index nested loops join is the fastest join operation because they require the least I/O and the fewest comparisons.
The nested loops join, also called nested iteration, uses one join input as the outer input table (shown as the top input in the graphical execution plan) and one as the inner (bottom) input table. The outer loop consumes the outer input table row by row. The inner loop, executed for each outer row, searches for matching rows in the inner input table.
Merge Joins
If the two join inputs are not small but are sorted on their join column (for example, if they were obtained by scanning sorted indexes), a merge join is the fastest join operation. If both join inputs are large and the two inputs are of similar sizes, a merge join with prior sorting and a hash join offer similar performance. However, hash join operations are often much faster if the two input sizes differ significantly from each other.
The merge join requires both inputs to be sorted on the merge columns, which are defined by the equality (ON) clauses of the join predicate. The query optimizer typically scans an index, if one exists on the proper set of columns, or it places a sort operator below the merge join. In rare cases, there may be multiple equality clauses, but the merge columns are taken from only some of the available equality clauses.
Hash Join
Hash joins can efficiently process large, unsorted, nonindexed inputs. They are useful for intermediate results in complex queries because:
- Intermediate results are not indexed (unless explicitly saved to disk and then indexed) and often are not suitably sorted for the next operation in the query plan.
- Query optimizers estimate only intermediate result sizes. Because estimates can be very inaccurate for complex queries, algorithms to process intermediate results not only must be efficient, but also must degrade gracefully if an intermediate result turns out to be much larger than anticipated.
Adaptive Joins
Batch mode Adaptive Joins enable the choice of a Hash Join or Nested Loops join method to be deferred until after the first input has been scanned. The Adaptive Join operator defines a threshold that is used to decide when to switch to a Nested Loops plan. A query plan can therefore dynamically switch to a better join strategy during execution without having to be recompiled.
WHERE filters
Specifies the search condition for the rows returned by the query.
WHERE conditions are applicable to all CRUD operations (SELECT, UPDATE, DELETE, INSERT (FROM))
-- Uses AdventureWorksDW
SELECT EmployeeKey, LastName
FROM DimEmployee
WHERE LastName = 'Smith' ;
or partial match (contains)
-- Uses AdventureWorksDW
SELECT EmployeeKey, LastName
FROM DimEmployee
WHERE LastName LIKE ('%Smi%');
or multi-condition where statements
-- Uses AdventureWorksDW
SELECT EmployeeKey, LastName
FROM DimEmployee
WHERE EmployeeKey = 1 OR EmployeeKey = 8 OR EmployeeKey = 12;
or in a set
-- Uses AdventureWorksDW
SELECT EmployeeKey, LastName
FROM DimEmployee
WHERE LastName IN ('Smith', 'Godfrey', 'Johnson');
or a value in a range
-- Uses AdventureWorksDW
SELECT EmployeeKey, LastName
FROM DimEmployee
WHERE EmployeeKey Between 100 AND 200;
WHERE ANY
SELECT ProductName
FROM Product
WHERE Id = ANY
(SELECT ProductId
FROM OrderItem
WHERE Quantity = 1)
WHERE ALL
SELECT DISTINCT FirstName + ' ' + LastName as CustomerName
FROM Customer, [Order]
WHERE Customer.Id = [Order].CustomerId
AND TotalAmount > ALL
(SELECT AVG(TotalAmount)
FROM [Order]
GROUP BY CustomerId)
Sub-Queries
A subquery is a query that is nested inside a SELECT, INSERT, UPDATE, or DELETE statement, or inside another subquery. A subquery can be used anywhere an expression is allowed. In this example a subquery is used as a column expression named MaxUnitPrice in a SELECT statement.
USE AdventureWorks2016;
GO
SELECT Ord.SalesOrderID, Ord.OrderDate,
(SELECT MAX(OrdDet.UnitPrice)
FROM Sales.SalesOrderDetail AS OrdDet
WHERE Ord.SalesOrderID = OrdDet.SalesOrderID) AS MaxUnitPrice
FROM Sales.SalesOrderHeader AS Ord;
GO