
Bayesian Networks as a probabilistic approach to solving common problems
Background
A Bayesian network is a graphical model that represents the probabilistic relationships among a set of variables. It’s particularly useful for modeling uncertainty and making decisions in situations where there are complex dependencies between variables. In the context of filling appointments at a doctor’s office, a Bayesian network can help optimize appointment scheduling by taking into account various factors that influence the likelihood of appointment availability and patient preferences.
Example - Why is the grass wet
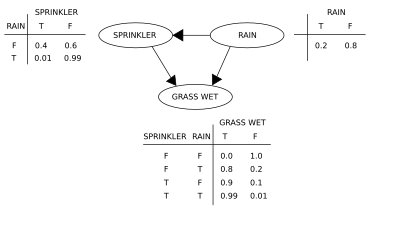
A simple Bayesian network with three nodes: “Rain,” “Sprinkler,” and “Grass Wet.”
-
Rain: This node represents whether it’s raining or not. It’s a parent node to the “Sprinkler” node. If it’s raining, it might influence whether the sprinkler is on or off.
-
Sprinkler: This node represents whether the sprinkler is on or off. It’s influenced by the “Rain” node, meaning that if it’s raining, the sprinkler might be off. The “Sprinkler” node is also a parent node to the “Grass Wet” node. If the sprinkler is on, it might influence whether the grass is wet.
-
Grass Wet: This node represents whether the grass is wet or not. It’s influenced by both the “Rain” and “Sprinkler” nodes. If it’s raining or the sprinkler is on, the grass might be wet.
The arrows in the diagram indicate the causal relationships and conditional dependencies between the variables. Here’s how the arrows can be interpreted:
- Rain influences Sprinkler: Rain affects the decision to turn on the sprinkler.
- Rain and Sprinkler both influence Grass Wet: If it’s raining or the sprinkler is on, the grass is likely to be wet.
In this Bayesian network, the relationships are quite intuitive:
- If it’s raining, it’s less likely that someone would turn on the sprinkler, and therefore, the grass is likely to be wet.
- If it’s not raining but the sprinkler is on, the grass might still be wet.
The structure and connections in this network allow for making probabilistic inferences about the state of the variables based on observations or evidence. For example, if you observe that the grass is wet, you can use this network to update the probabilities of it being caused by rain or the sprinkler being on.
Example - Appointment Scheduling
Here’s how a Bayesian network approach could be used for appointment scheduling:
Variables:
- Time Slots: Discrete variables representing different available time slots for appointments. Doctor’s Availability: Binary variable indicating whether the doctor is available during a specific time slot.
- Patient Preferences: Variables representing patient preferences, such as preferred day of the week, time of day, or specific doctor.
- Urgency: Variable representing the urgency of the patient’s condition, which can affect appointment priorities.
- Cancellation Probability: Probability that an already scheduled appointment might be canceled.
Dependencies:
- Doctor’s Availability and Time Slots: The doctor’s availability directly affects which time slots can be scheduled.
- Patient Preferences and Time Slots: Patient preferences influence the desirability of different time slots.
- Urgency and Appointment Priority: More urgent cases might need to be prioritized over less urgent ones.
- Cancellation Probability and Appointment Rescheduling: If the cancellation probability is high, the system might overbook certain slots to account for potential cancellations.
Bayesian Network Structure:
The Bayesian network would be structured with nodes representing the variables mentioned above and edges connecting nodes that have direct dependencies. The conditional probabilities associated with the edges would be determined based on historical data, expert opinions, or a combination of both.
-
Inference and Decision-Making: Given a set of patient appointment requests and the current state of the schedule, the Bayesian network can perform inference to compute the probabilities of different scenarios:
-
Appointment Availability: Given a patient’s preferences and the doctor’s availability, the network can estimate the probability of finding a suitable appointment slot.
-
Appointment Priority: By incorporating the urgency of the patient’s condition, the network can prioritize appointments accordingly.
-
Overbooking Decision: If the cancellation probability is high, the network might decide to overbook certain slots with a calculated probability to mitigate the impact of cancellations.
-
Optimization: The Bayesian network approach allows for optimizing the appointment scheduling process by considering a multitude of factors and uncertainties simultaneously. The network can make informed decisions about appointment assignments, considering both patient preferences and the doctor’s availability, while also accounting for the potential variability due to cancellations.
Overall, a Bayesian network approach provides a flexible and probabilistic framework for making effective appointment scheduling decisions in a doctor’s office, taking into account the inherent complexities and uncertainties of the process.
Training a Bayesian network
Training a Bayesian network involves learning the conditional probability distributions (CPDs) of the variables in the network based on observed data. In the context of appointment scheduling, you would need historical data on appointment requests, doctor availability, patient preferences, urgencies, cancellations, and the corresponding time slots assigned.
Here’s how you might approach training the Bayesian network using historical data:
-
Data Collection: Gather historical data from your appointment scheduling system. This data should include information about each appointment request, such as patient preferences, doctor availability, urgency, whether the appointment was scheduled, and if applicable, whether it was later canceled.
-
Data Preprocessing: Clean and preprocess the data to ensure it’s in a suitable format for training. This might involve handling missing values, encoding categorical variables, and transforming data as needed.
-
Define the Network Structure: Based on your domain knowledge, define the structure of the Bayesian network by identifying the variables and their dependencies. This step involves determining which variables influence each other and how they are connected in the network.
-
Learning CPDs: Estimate the conditional probability distributions (CPDs) for each variable in the network. You can use techniques like Maximum Likelihood Estimation (MLE) or Bayesian parameter estimation. The choice of estimation method depends on the nature of the data and the characteristics of the variables.
For example, to learn a CPD for a discrete variable like “TimeSlots” given the evidence of “DoctorAvailability,” “PatientPreferences,” “Urgency,” and “CancellationProbability,” you would calculate the probabilities from the historical data for each possible combination of values for the variables.
P(TimeSlots | DoctorAvailability, PatientPreferences, Urgency, CancellationProbability)
-
Model Evaluation: Split your historical data into a training set and a validation set. Use the training set to learn the CPDs and the validation set to assess the performance of the Bayesian network. You might use metrics like log-likelihood or accuracy to evaluate how well the model captures the relationships in the data.
-
Refinement: Based on the evaluation results, refine your Bayesian network model. You can adjust the network structure, consider additional variables, or try different parameter estimation methods to improve its performance.
-
Validation and Testing: Once you’re satisfied with the model’s performance on the validation set, you can test it on a separate test dataset to assess its generalization to new data.
It’s important to note that training a Bayesian network requires a good amount of data and domain expertise. The quality of your model’s predictions will largely depend on the quality of the data you have and the assumptions you make about the relationships between variables. Additionally, Bayesian networks might not capture all the complexities of real-world systems, and trade-offs between simplicity and accuracy need to be considered.
Example training appointment scheduling
To train a Bayesian network using Python, you can use the pgmpy library. In this example, I’ll show you how to simulate some synthetic data and then use that data to learn the parameters (CPDs) of a simple Bayesian network structure. Remember that real-world data would be more complex and require proper preprocessing.
from pgmpy.models import BayesianNetwork
from pgmpy.factors.discrete import TabularCPD
from pgmpy.estimators import ParameterEstimator, MaximumLikelihoodEstimator
import numpy as np
# Define the variables
variables = ['TimeSlots', 'DoctorAvailability', 'PatientPreferences', 'Urgency', 'CancellationProbability']
# Initialize the Bayesian Network
network = BayesianNetwork(variables)
# Define the dependencies
network.add_edge('DoctorAvailability', 'TimeSlots')
network.add_edge('PatientPreferences', 'TimeSlots')
network.add_edge('Urgency', 'TimeSlots')
network.add_edge('CancellationProbability', 'TimeSlots')
# Generate synthetic data (you would replace this with your real data)
np.random.seed(0)
num_samples = 1000
data = np.random.randint(2, size=(num_samples, len(variables)))
# Convert data to a dictionary for training
data_dict = {variable: data[:, idx] for idx, variable in enumerate(variables)}
# Initialize Maximum Likelihood Estimator
mle = MaximumLikelihoodEstimator(network, data_dict)
# Learn CPDs from the data
cpds = mle.get_parameters()
# Print the learned CPDs
for variable, cpd in cpds.items():
print(f'CPD for {variable}:\n{cpd}\n')
In this example, synthetic data is generated using NumPy to simulate a binary state for each variable. In a real-world scenario, you would replace the synthetic data with your actual historical data.
The MaximumLikelihoodEstimator in pgmpy is used to estimate the CPDs based on the provided data. The get_parameters() method returns a dictionary of CPDs for each variable in the network.
Please note that this example assumes a very simple network structure and synthetic data for demonstration purposes. In a real-world application, you would need to preprocess your data, design a meaningful network structure, and make appropriate modifications to handle continuous variables, missing data, and other complexities.
Inference using a Bayesian network
Creating a full Bayesian network for appointment scheduling in Python would require a comprehensive library specifically designed for probabilistic graphical models. One popular library for this purpose is pgmpy (Probabilistic Graphical Models using Python).
Here’s a simplified example of how you might structure a Bayesian network using pgmpy to assist with appointment scheduling:
from pgmpy.models import BayesianNetwork
from pgmpy.factors.discrete import TabularCPD
from pgmpy.inference import VariableElimination
# Define the variables
variables = ['TimeSlots', 'DoctorAvailability', 'PatientPreferences', 'Urgency', 'CancellationProbability']
# Initialize the Bayesian Network
network = BayesianNetwork(variables)
# Define conditional probability distributions (CPDs)
cpd_time_slots = TabularCPD(variable='TimeSlots', variable_card=3, values=[[0.4], [0.4], [0.2]])
cpd_doctor_availability = TabularCPD(variable='DoctorAvailability', variable_card=2, values=[[0.8], [0.2]])
cpd_patient_preferences = TabularCPD(variable='PatientPreferences', variable_card=3, values=[[0.3], [0.4], [0.3]])
cpd_urgency = TabularCPD(variable='Urgency', variable_card=2, values=[[0.7], [0.3]])
cpd_cancellation_probability = TabularCPD(variable='CancellationProbability', variable_card=2, values=[[0.8], [0.2]])
# Define the dependencies
network.add_edge('DoctorAvailability', 'TimeSlots')
network.add_edge('PatientPreferences', 'TimeSlots')
network.add_edge('Urgency', 'TimeSlots')
network.add_edge('CancellationProbability', 'TimeSlots')
# Add CPDs to the network
network.add_cpds(cpd_time_slots, cpd_doctor_availability, cpd_patient_preferences, cpd_urgency, cpd_cancellation_probability)
# Initialize Variable Elimination for inference
inference = VariableElimination(network)
# Example inference
appointment_availability = inference.query(variables=['TimeSlots'], evidence={'DoctorAvailability': 1, 'PatientPreferences': 2, 'Urgency': 1})
print(appointment_availability)
# Example of finding the probability of a specific scenario
probability_scenario = inference.query(variables=['TimeSlots'], evidence={'DoctorAvailability': 1, 'PatientPreferences': 1, 'Urgency': 0})
print(probability_scenario)
Please note that this example is greatly simplified and may not cover all the nuances and complexities of a real-world appointment scheduling system. It’s recommended to consult the documentation of the pgmpy library for more advanced use cases and features. Additionally, building a fully-fledged appointment scheduling system would require more detailed data, sophisticated CPD structures, and potentially more variables to account for various factors influencing appointment availability.